非靶向代谢组学(LC-HRMS)是解析中药、食品等复杂体系时常用的技术工具。然而,许多研究者在数据解析的第一步——峰提取——就面临挑战:数以万计的“候选特征峰”中,往往混杂着大量的假阳性信号。
这些由噪声、同位素峰、加合离子等构成的“伪峰”,不仅淹没了真正的代谢物信息,还可能导向错误的研究结论。
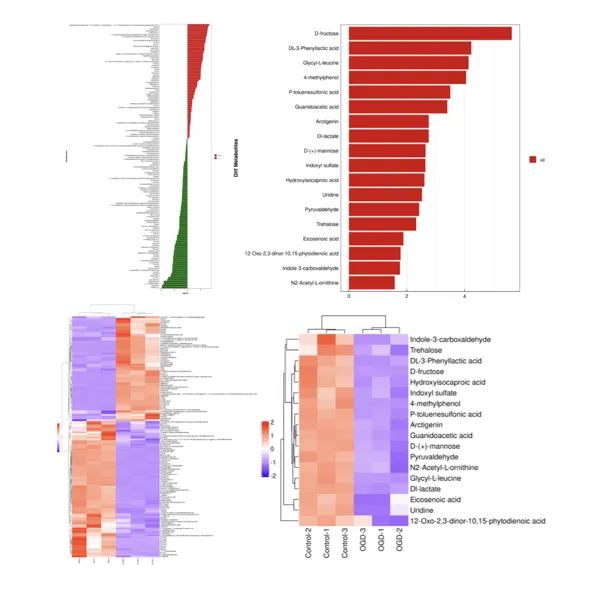
为什么非靶向代谢组学会产生假阳性?
在实际检测中,假阳性信号的出现主要源于以下三个方面:
1. 峰提取参数过宽:如同用大网捕鱼,在收集目标信号的同时,杂质信号也一并被捞起。
2. 同位素与加合峰未有效剔除:一个真实的代谢物在质谱中会衍生出多个不同的信号,若不加以识别,就会被误认为是多个不同的化合物。
3. 一级质谱(MS1)匹配容差过大:低精度匹配容易导致“张冠李戴”,将不相关的物质归为同一类。
为了帮助研究人员从源头提升数据质量,成分宝实验室推荐以下“三步净化法”来优化数据分析流程。
第一步:利用软件进行智能去噪
在数据处理初期,可以利用 MS-DIAL 等工具的先进算法,自动识别并清除同位素簇和化学噪声。这一步骤特别适用于中药等超高复杂度的基质,能够有效为庞大的原始数据“瘦身”,排除背景干扰。
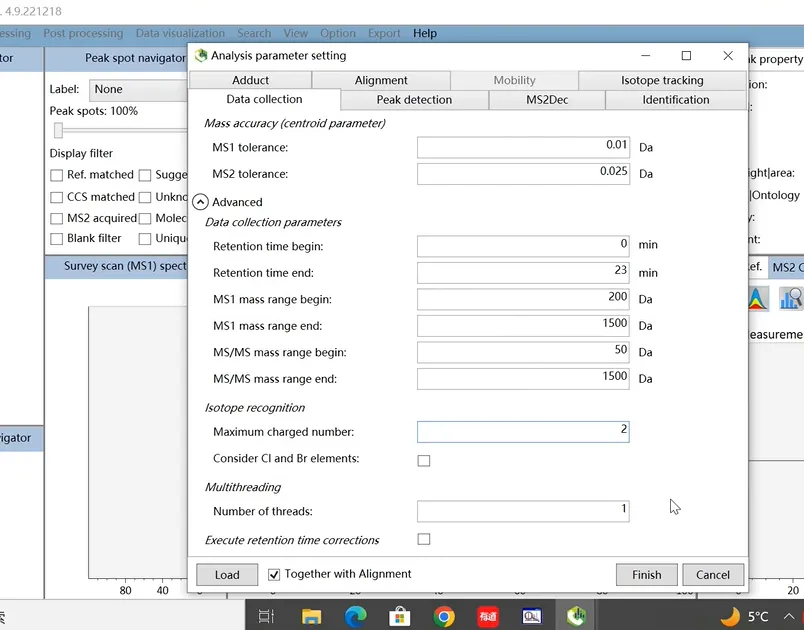
第二步:严格控制质量精度
充分发挥高分辨率质谱仪的精度优势。在数据处理时,建议将质量容差(m/z)收紧至 5 ppm 以内。这是大幅降低误注释率、提高定性准确性的关键步骤。
第三步:RT、MS双重匹配与MS/MS碎片验证
单一的质量数匹配往往不够安全,我们需要引入多重验证机制:
- 双重筛选:通过保留时间(RT)和精确质量(m/z)进行初级锁定,缩小候选范围。
- 碎片确认:引入二级碎片谱图(MS/MS)与标准数据库进行比对匹配,为化合物的结构鉴定提供更多证据。
优化后的实际效果与应用场景
经过这三步筛选与净化,特征峰列表的数量通常会有所缩减,但留下来的信号整体更接近高置信度候选。这不仅降低了后续数据分析的噪音,也能为后续生物标志物发现、代谢通路分析提供更可靠的数据基础。

成分宝检测实验室专注于中药、食品、化妆品的非靶向代谢组分析与配方还原。如果您在成分检测、数据去噪或配方解析过程中遇到技术瓶颈,欢迎下单咨询工程师,我们会结合样品类型和检测目标,协助评估合适的技术方案。